#
Summarize
#
O que é?
Esta extensão permite que você crie, armazene e utilize resumos gerados automaticamente com base nos eventos que acontecem em seus chats. A sumarização pode ajudar a delinear detalhes gerais do que está acontecendo na história, o que pode ser interpretado como uma memória de longo prazo, mas tome essa afirmação com cautela. Como os resumos são gerados por modelos de linguagem, as saídas podem perder alguns detalhes importantes ou conter alucinações, portanto, é sempre aconselhável acompanhar o estado do resumo e corrigi-lo manualmente se necessário.
#
Configuração comum
A extensão de sumarização está instalada no SillyTavern por padrão, assim ela aparecerá na lista do painel Extensions do ST (ícone de cubos empilhados) assim:
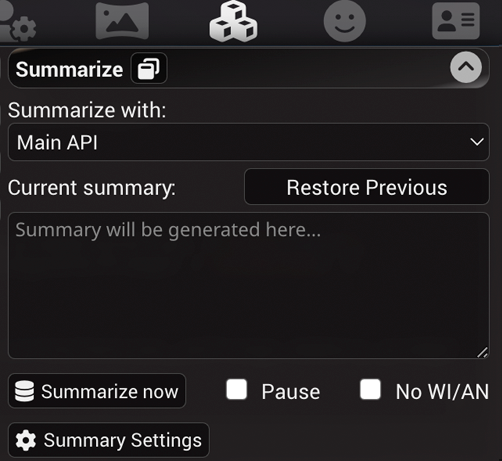
- Current summary - exibe e fornece a capacidade de modificar o resumo atual. O resumo é atualizado e incorporado nos metadados do arquivo de chat para a mensagem que foi a última no contexto quando o resumo foi gerado. Excluir ou editar uma mensagem do chat que tem um resumo anexado a ela reverterá o estado para o último resumo válido.
- Restore Previous - remove o resumo atual, revertendo-o para o estado anterior. Isso é útil se o sumarizador fizer um trabalho ruim em qualquer ponto.
- Pause - marque isso para evitar que o resumo seja atualizado automaticamente. Isso é útil se você quiser fornecer um resumo personalizado próprio ou para efetivamente desabilitar o resumo limpando a caixa e parando as atualizações.
- Popup window - permite desanexar o resumo em um painel de UI móvel na barra lateral. Útil para o layout de desktop para ter fácil acesso às configurações de sumarização sem ter que navegar pelo menu de extensões.
- Injection Template - define como o resumo será envolvido ao ser inserido em prompts de chat regulares. Uma macro especial {{summary}} deve ser usada para denotar a localização exata do estado atual do resumo no texto de injeção do prompt.
- Injection Position - define a localização da injeção do prompt. As opções são as mesmas que para Author's Notes: antes ou depois do prompt principal, ou no chat em profundidade designada.
#
Fontes de resumo suportadas
#
API Principal
A sumarização será alimentada pelo seu backend de IA, modelo e configurações atualmente selecionados. Este método não requer configuração adicional, apenas uma conexão de API funcionando.
Esta opção tem os seguintes submodos que diferem dependendo de como o prompt de resumo é construído:
- Raw, bloqueante. O resumo será gerado usando nada além do prompt de sumarização e o histórico de chat. Prompts subsequentes também incluirão o resumo anterior com mensagens que foram enviadas após o resumo ser gerado (veja o exemplo). Este modo pode (e irá) gerar prompts que têm muita variabilidade entre eles, portanto não é recomendado usá-lo com backends que têm tempos de processamento de prompt lentos, como llama.cpp e seus derivados.
- Raw, não bloqueante. Igual ao anterior, mas a geração de chat não será bloqueada durante a geração do resumo. Nem todos os backends suportam solicitações simultâneas, então mude para o modo bloqueante se a sumarização falhar.
- Classic, bloqueante. O prompt de sumarização será enviado no final do seu prompt de geração usual, como uma instrução de sistema neutra, não omitindo o cartão de personagem, prompt principal, diálogos de exemplo e outras partes dos prompts de chat. Isso geralmente resulta em prompts que funcionam bem com a reutilização de prompts processados, então é recomendado usar com llama.cpp e seus irmãos.
#
Configurações de Resumo explicadas
- Summary Prompt - define o prompt que será usado para criar um resumo. Pode incluir qualquer uma das macros conhecidas, bem como uma macro especial {{words}} (veja abaixo).
- Target summary length (words) - define o valor da macro {{words}} que pode ser inserida no Summary Prompt. Esta configuração é completamente opcional e não tem efeito algum se a macro não for usada.
- API response length (tokens) - permite definir uma substituição do comprimento de resposta da API para gerar resumos que são diferentes do valor definido globalmente.
- Max messages per request (apenas modos raw) - defina para limitar o número máximo de mensagens que serão incluídas em um prompt de sumarização.
0significa nenhuma limitação explícita, mas o número resultante de mensagens a serem resumidas ainda dependerá do tamanho máximo do contexto, calculado usando a fórmula:buffer de resumo máximo = tamanho do contexto - prompt de sumarização - resumo anterior - comprimento de resposta. Use isso quando quiser obter resumos mais focados em modelos com tamanhos de contexto grandes. - No WI/AN - omite World Info e Author's Note do texto a ser resumido. Só tem efeito ao usar o construtor de prompt Classic. O construtor de prompt Raw sempre omite WI/AN.
- Update every X messages - define o intervalo no qual o resumo é gerado.
0significa que a sumarização automática está desabilitada, mas você ainda pode acioná-la manualmente clicando no botão "Summarize now". Isso deve ser ajustado com base em quão rapidamente o buffer de prompt se enche completamente com mensagens de chat. Idealmente, você gostaria de ter o primeiro resumo gerado quando as mensagens começam a ser descartadas do prompt. - Update every X words - o mesmo que acima, mas usando palavras (não tokens!) em vez de mensagens, teoricamente pode ser uma medida mais precisa devido à imprevisibilidade do conteúdo das mensagens de chat geralmente, mas sua experiência pode variar.
Se ambos os controles deslizantes "Update every" forem definidos com um valor diferente de zero, então ambos acionarão atualizações de resumo em seus respectivos intervalos, dependendo do que acontecer primeiro. É fortemente aconselhável atualizar esses valores adequadamente quando você mudar para outro modelo que tem tamanhos de contexto diferentes, caso contrário, a geração de resumo pode acionar com muita frequência ou nunca.
Se você não tem certeza sobre as configurações de intervalo, pode clicar no botão "varinha mágica" acima dos controles deslizantes "Update every" para tentar adivinhar os valores ideais com base em algumas heurísticas simples. Uma breve descrição do algoritmo é a seguinte:
- Calcular contagens de tokens e palavras para todas as mensagens de chat
- Determinar o comprimento alvo do resumo com base nas palavras desejadas do prompt
- Calcular o número máximo de mensagens que podem caber no prompt com base no comprimento médio da mensagem
- Se "Max messages" estiver definido, ajustar a média para contabilizar mensagens que não se encaixam no limite do resumo
- Arredondar para baixo a média ajustada de mensagens por prompt para um múltiplo de 5
#
Exemplos de prompts
Prompt Raw
System:
[Prompt de sumarização]
Resumo anterior.
User:
Mensagem foo.
Char:
Mensagem bar.Prompt Classic
[Prompt principal]
[Cartão de personagem]
[Diálogos de exemplo]
User:
Mensagem foo.
Char:
Mensagem bar.
System:
[Prompt de sumarização]
#
API Extras
O servidor Extras com o módulo summarize pode executar um modelo de sumarização auxiliar (BART).
Ele tem um tamanho de contexto muito pequeno (~1024 tokens), então sua capacidade de lidar com resumos grandes é bastante limitada.
Para configurar a fonte de resumo Extras, faça o seguinte:
- Instale ou Atualize o Extras para a versão mais recente.
- Execute o Extras com o módulo
summarizehabilitado:python server.py --enable-modules=summarize
#
Mudando o Modelo de Resumo
Por padrão, Summarize usa o modelo Qiliang/bart-large-cnn-samsum-ChatGPT_v3 para fins de sumarização.
Isso pode ser alterado usando o argumento de linha de comando --summarization-model=(###Hugging-Face-Model-URL-Here###)
Um modelo alternativo de Summarize conhecido é Qiliang/bart-large-cnn-samsum-ElectrifAi_v10.