#
KoboldCpp
KoboldCpp é uma API autônoma para modelos GGML e GGUF.
Esta Calculadora de VRAM por Nyx dirá aproximadamente quanta RAM/VRAM seu modelo requer.
#
Início Rápido para GPU Nvidia
Este guia assume que você está usando Windows.
- Baixe a versão mais recente: https://github.com/LostRuins/koboldcpp/releases
- Inicie o KoboldCpp. Você pode ver um pop-up do Microsoft Defender, clique em
Run Anyway. - A partir da versão 1.58, o KoboldCpp deve se parecer com isto:
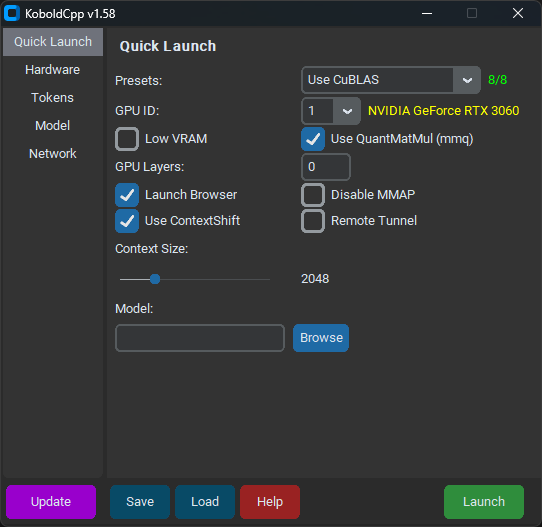
- Na aba
Quick Launch, selecione o modelo e seuContext Sizepreferido. - Selecione
Use CuBLASe certifique-se de que o texto amarelo ao lado deGPU IDcorresponde à sua GPU. - Não marque
Low VRAM, mesmo se você tiver pouca VRAM. - A menos que você tenha uma GPU Nvidia série 10 ou mais antiga, desmarque
Use QuantMatMul (mmq). GPU Layersdeve ter sido preenchido quando você carregou seu modelo. Deixe-o lá por enquanto.- Na aba
Hardware, marqueHigh Priority. - Clique em
Savepara não ter que configurar o KoboldCpp a cada inicialização. - Clique em
Launche aguarde o modelo carregar.
Você deve ver algo assim:
Load Model OK: True
Embedded Kobold Lite loaded.
Starting Kobold API on port 5001 at http://localhost:5001/api/
Starting OpenAI Compatible API on port 5001 at http://localhost:5001/v1/
======
Please connect to custom endpoint at http://localhost:5001Agora você pode se conectar ao KoboldCpp no SillyTavern com http://localhost:5001 como a URL da API e começar a conversar.
Parabéns! Você terminou!
Mais ou menos.
#
GPU Layers
O KoboldCpp está funcionando, mas você pode melhorar o desempenho garantindo que o máximo de camadas possível sejam transferidas para a GPU. Você deve ver algo assim no terminal:
llm_load_tensors: offloading 9 repeating layers to GPU
llm_load_tensors: offloaded 9/33 layers to GPU
llm_load_tensors: CPU buffer size = 25215.88 MiB
llm_load_tensors: CUDA0 buffer size = 7043.34 MiB
....................................................................................................
llama_kv_cache_init: CUDA_Host KV buffer size = 1479.19 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 578.81 MiBNão tenha medo de números; esta parte é mais fácil do que parece. CPU buffer size refere-se a quanta RAM do sistema está sendo usada. Ignore isso. CUDA0 buffer size refere-se a quanta VRAM da GPU está sendo usada. CUDA_Host KV buffer size e CUDA0 KV buffer size referem-se a quanta VRAM da GPU está sendo dedicada ao contexto do seu modelo. Neste caso, o KoboldCpp está usando cerca de 9 GB de VRAM.
Eu tenho 12 GB de VRAM, e apenas 2 GB de VRAM estão sendo usados para contexto, então tenho cerca de 10 GB de VRAM sobrando para carregar o modelo. Como 9 camadas usaram cerca de 7 GB de VRAM e 7000 / 9 = 777.77, podemos assumir que cada camada usa aproximadamente 777.77 MIB de VRAM. 10.000 MIB / 777.77 = 12.8, então vou arredondar para baixo e carregar 12 camadas com este modelo de agora em diante.
Agora faça sua própria matemática usando o modelo, tamanho de contexto e VRAM para o seu sistema, e reinicie o KoboldCpp:
- Se você for esperto, clicou em
Saveantes, e agora pode carregar sua configuração anterior comLoad. Caso contrário, selecione as mesmas configurações que você escolheu antes. - Mude o
GPU Layerspara o seu novo número otimizado para VRAM (12 camadas no meu caso). - Clique em
Savepara salvar sua configuração atualizada.
Agora você deve ver algo assim:
llm_load_tensors: offloading 12 repeating layers to GPU
llm_load_tensors: offloaded 12/33 layers to GPU
llm_load_tensors: CPU buffer size = 25215.88 MiB
llm_load_tensors: CUDA0 buffer size = 9391.12 MiB
....................................................................................................
llama_kv_cache_init: CUDA_Host KV buffer size = 1286.25 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 771.75 MiBO KoboldCpp está usando cerca de 11.5 GB dos meus 12 GB de VRAM. Isso deve ter um desempenho muito melhor do que as configurações geradas automaticamente pelo KoboldCpp.
Parabéns! Você (realmente) terminou!
Para uma visão mais aprofundada das configurações do KoboldCpp, confira o Simple Llama + SillyTavern Setup Guide do Kalomaze.